Approach & Implmentation
We consider the method of style transfer, which will adopt destination’s appearance to source’s images. The existing approach to do is Generative Adversarial Network(GAN). In GAN, we train 2 models simultaneously, one is generator, which will generate destination’s image from source input(the “fake” destination image), and another is discriminator, which will classify the images as either the real destination image or the generated “fake” image. There are several notable variants in GAN, including DCGan, pix2pix, CycleGan, etc.
Attempt - Pix2Pix
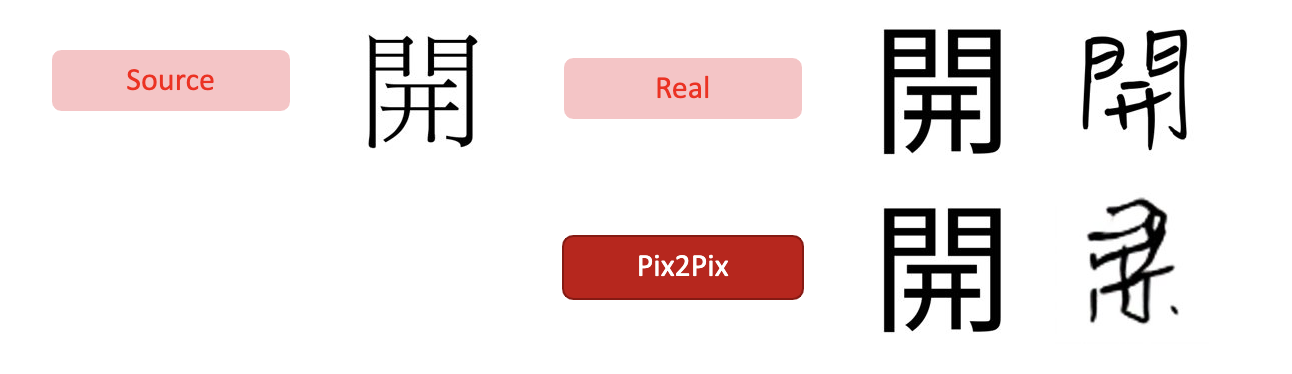
Pix2Pix uses conditional GAN as the solution to image-to-image translation problem, which needs paired (dst,src) as training input. Below are two examples that this model can effetively complete.

However, this method requires "pixel to pixel" mapping, so it can work well if the font style is not significantly different but is unusable in handwriting style font, where the pixel has no direct relation to.
Dataset
Dataset is generated from existing font file (.ttf).

Implemented models
We implemented the following models using pytorch. We also unified the generator and discriminator's interface, so different generator and discriminators can be hot-plugged to the code.
1. CycleGAN and DiscoGAN
First we implemented a baseline Cycle Gan model. Cycle Gan is an unpaired image-to-image translation method proposed by Zhu[2] etc. It contains 2 Generators, one generated the font from source font image to destination font image(the "fake" destination font), and another generated from destination to source(the "fake" source font), and 2 Discriminators classifying the destination font and the source font. In cycleGan, it will use the "fake" destination font to generate a "fake fake" source font, and using this font and the original source font(the "real" source) to calculate L1 loss as the forward cycle-consistency loss, since we would hope the fake fake source is close to the real source font. Similarly, there is a backward cycle-consistency loss calculating between the fake fake destination(genereated by fake source font) and the real destination.
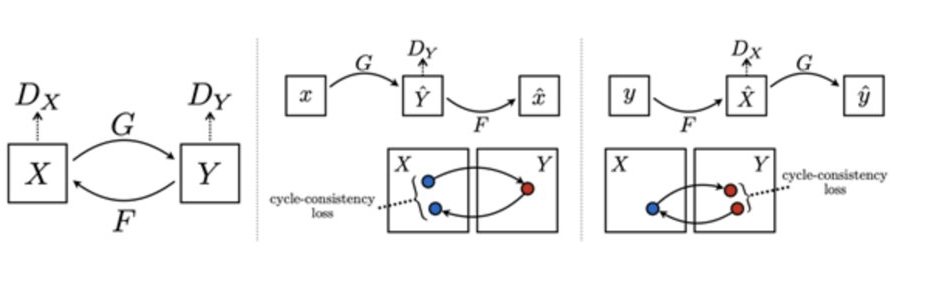
There’s another similar GAN, the discoGAN, using the same idea, but with different model structure as the below image showed, and it utilized the mean square error loss to replace the L1 loss.
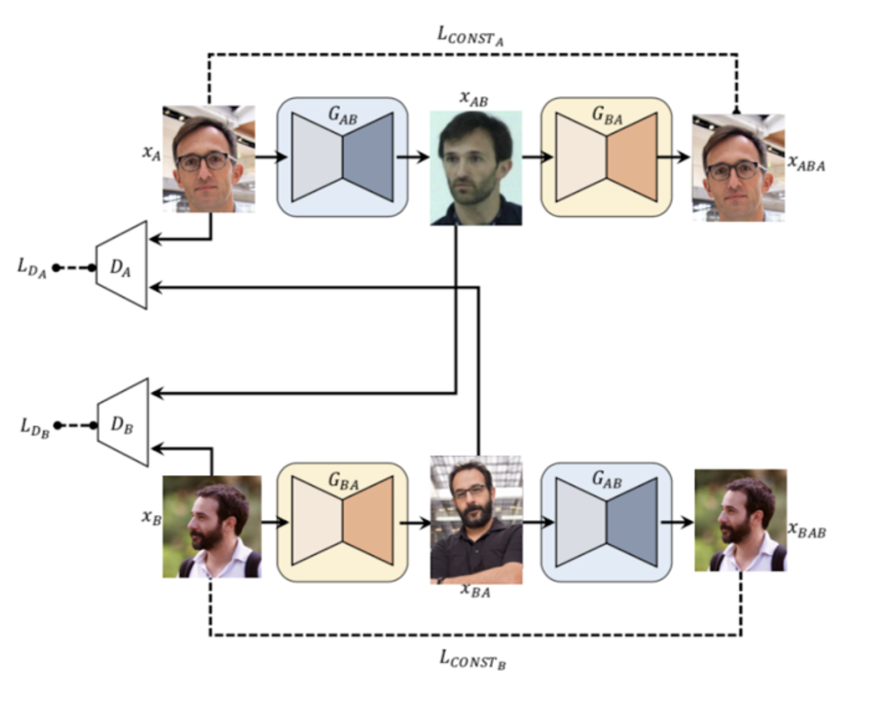
2. DualGAN
We then attemped to plug-in DualGAN's generator and discriminator. DualGAN is a model purposed by Yi[1] etc. For the generator part, it adopts the U-shape net structure. This helps the model to share low-level information and keep the alignment of the image structures.
For the discriminator part, it employs the Markovian PatchGAN model. It keeps the independence between pixels distanced beyond a specific patch size and it is effective in capturing ocal high frequency.
All above characteristics of DualGAN contributes to a more stable output structure. However, too much constraints may also lead to the underfitting problem.
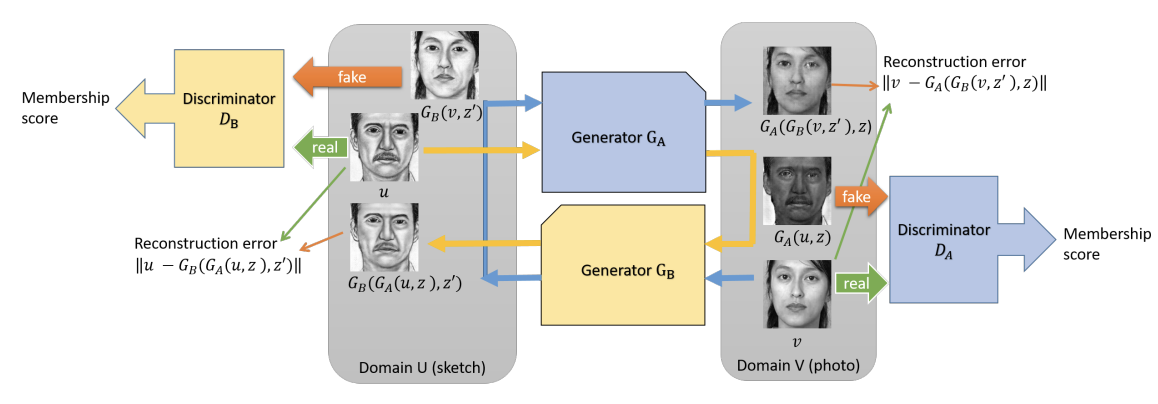
3. Our methods
Now we will describe our modification. We decide to modify based on CycleGAN since it performed the best based on our previous experiments. Some notable modifications include changing the loss function to MSE as in DiscoGAN since it is more sensitive to shape changes (again based on our previous experiments). We also noticed that it is easy to generate paired data in our use case so we introduced a "true loss" to the loss function, which is the mse compared to the ground truth. Additionally, we also add some preprocessing including random flips and converting images to grayscale.
References
- Yi, Zili & Zhang, Hao & Tan, Ping & Gong, Minglun. (2017). DualGAN: Unsupervised Dual Learning for Image-to-Image Translation. 2868-2876. 10.1109/ICCV.2017.310.
- Zhu, J.-Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired image-to-image translation using cycle-consistent adversarial networks. 2017 IEEE International Conference on Computer Vision (ICCV).